
当今,生成式 AI 技术已经成为推动创新和数字转型的关键力量,而 DeepSeek-R1 作为一款强大的基础模型,凭借其高效的推理能力和低资源消耗,成为了开发者的首选。随着 AWS 提供的灵活部署选项和强大的基础设施,您可以轻松将 DeepSeek-R1 快速部署到云端,从而实现高效的生成式 AI 应用。本文将为您介绍如何在 AWS 上快速部署 DeepSeek-R1 模型,助力您在云端构建可扩展、可靠的 AI 解决方案。
通过亚马逊云科技部署DeepSeek的优势
亚马逊云科技作为全球领先的云计算平台,为 AI 模型提供了高性能、可扩展、低成本的计算基础设施,帮助企业和开发者轻松部署和优化 AI 模型。
在亚马逊云科技的高性能计算环境支持下,DeepSeek R1 能够提供低延迟、高吞吐的推理体验,为企业 AI 应用提供强大的支撑,尤其适用于需要实时响应、数据量庞大的业务场景。
如何在亚马逊云科技部署 DeepSeek R1 模型?
01. 进入 Amazon SageMaker
在SageMaker中,可以使用托管端点部署 DeepSeek R1。
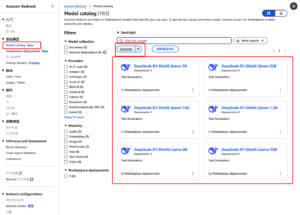
02. 部署 DeepSeek R1 模型
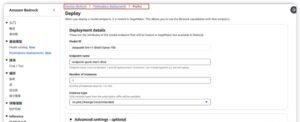
03. 启动推理服务
完成部署后,企业可以立即在亚马逊云科技中启动 DeepSeek R1 模型的推理服务,通过 API 调用模型,实现智能化的数据处理、语音识别、自然语言交互等 AI 任务。
*DeepSeek R1 版本区别:
根据不同的业务需求,DeepSeek R1 提供了多个参数规模的模型,以适配不同计算资源的应用场景。
| DeepSeek-R1-Distill-Qwen-1.5B | 约 15 亿个参数 | 适用于计算资源有限但仍需强大性能的轻量级应用,如基础 NLP 任务或小规模文本生成。 |
| DeepSeek-R1-Distill-Qwen-7B | 约 70 亿个参数 | 适用于需要更强性能且希望平衡资源消耗的应用,如中小型企业的智能客服、文本生成。 |
| DeepSeek-R1-Distill-Qwen-8B | 约 80 亿个参数 | 性能较强,适合中等规模的数据处理和处理较复杂的语境理解任务,如中等规模的 NLU 应用。 |
| DeepSeek-R1-Distill-Qwen-14B | 约 140 亿个参数 | 提供更高的推理能力,适合大规模的语言任务和复杂应用,如多轮对话系统、机器翻译。 |
| DeepSeek-R1-Distill-Qwen-32B | 约 32 亿个参数 | 适用于要求极高推理性能和精确度的场景,如高级 AI 研究、高复杂度的多模态任务。 |
| DeepSeek-R1-Distill-Llama-8B | 约 80 亿个参数 | 适用于跨语言的文本生成、英文 NLP 任务,如机器翻译、情感分析。 |
| DeepSeek-R1-Distill-Llama-70B | 约 700 亿个参数 | 适用于超大规模跨语言 NLP 任务和复杂 AI 应用,如大规模知识图谱构建、语言理解等。 |
借助亚马逊云科技的弹性计算能力,企业可以根据业务需求选择合适的模型版本,在成本和性能之间找到最佳平衡。
03.即刻部署,抢占 AI 先机!
AI 时代已经来临,DeepSeek R1 模型的亚马逊云科技部署方案为企业和开发者提供了一个低成本、高性能的 AI 解决方案。通过 AWS 的强大基础设施,你可以轻松部署 DeepSeek R1,并快速将 AI 应用集成到业务中,提升产品智能化水平。







