
Anthropic 宣布推出其最新的 AI 语言模型Claude 3.5 Sonnet ,这是推出的Claude 3构建的全新“3.5”模型系列中的第一个。Claude 3.5 可以撰写文本、分析数据和编写代码。它具有一个 200,000 个 token 上下文窗口,现已在Claude 网站上和通过 API 提供。Anthropic 还推出了 Artifacts,这是 Claude 界面中的一项新功能,可在专用窗口中显示相关工作文档。
我们Oncloud AI通过本文详细探讨Claude 3.5 Sonnet。
大型语言模型 (LLM) 的基准测试很麻烦,因为它们可能经过精心挑选,而且通常无法捕捉到使用机器生成几乎任何可以想象到的主题的输出的感觉和细微差别。但根据 Anthropic 的说法,Claude 3.5 Sonnet 在某些基准测试(如MMLU(本科水平知识)、GSM8K(小学数学)和HumanEval(编码))上的表现与 GPT-4o 和 Gemini 1.5 Pro 等竞争模型相当或优于它们。
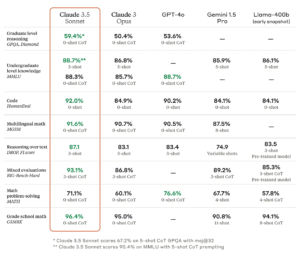 Claude 3.5 Sonnet 在衡量“推理”、数学技能、常识和编码能力的基准测试中也优于 Anthropic 之前的最佳模型 (Claude 3 Opus)。例如,该模型在内部编码评估中表现出色,解决了 64% 的问题,而 Claude 3 Opus 的问题解决率为 38%。
Claude 3.5 Sonnet 在衡量“推理”、数学技能、常识和编码能力的基准测试中也优于 Anthropic 之前的最佳模型 (Claude 3 Opus)。例如,该模型在内部编码评估中表现出色,解决了 64% 的问题,而 Claude 3 Opus 的问题解决率为 38%。
Claude 3.5 Sonnet 也是一个多模式 AI 模型,可以接受图像形式的视觉输入,据报道,新模型在一系列视觉理解测试中表现出色。

粗略地说,视觉基准测试表明 3.5 Sonnet 在从图像中提取信息方面比之前的模型做得更好。例如,你可以向它展示一张戴着橄榄球头盔的兔子的照片,模型知道这是一只戴着橄榄球头盔的兔子,并且可以谈论它。这对于技术演示来说很有趣,但对于可靠性至关重要的技术应用来说,这项技术仍然不够准确。
介绍“Artifacts”
对于普通用户来说,更值得注意的是一个名为“Artifacts”的新界面功能,它允许人们在对话的同时在专用窗口中与 Claude 生成的内容(如代码、文本和网页设计)进行交互。
Anthropic 将此视为将 Claude.ai(其网络界面)发展为团队协作工作空间的一步,但它也能帮助人们在处理某些工作时不会在长时间对话的积压中丢失内容。
Anthropic 表示,Claude 3.5 Sonnet 的运行速度是 Claude 3 Opus 的两倍。在性能大致相当的情况下,它的价格也更便宜——在 API 中,新的 3.5 型号每百万输入令牌的成本为 3 美元,每百万输出令牌的成本为 15 美元。相比之下,Opus 每百万输入令牌的成本为 15 美元,每百万输出令牌的成本为 75 美元。
除了网站和 API 之外,Claude 3.5 Sonnet 还可通过 Claude iOS 应用访问,付费用户的使用限制更高。该模型还可通过亚马逊的 Bedrock 和 Google Cloud 的 Vertex AI 平台使用。








