
Anthropic 為其AI 產品線推出了兩項重大升級:Claude 3.5 Sonnet 和Claude 3.5 Haiku。除了這些改進之外,一項新的電腦使用功能也已在公開測試版中推出。這些發展突破了自動化、編碼和電腦導航的界限,為開發人員和企業帶來了新的可能性。 我們Oncloud AI透過本文詳細探討Claude 3.5 Sonnet 和Claude 3.5 Haiku。
Claude 3.5 Sonnet:增強軟體工程
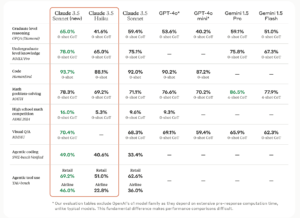
Claude 3.5 Sonnet 比其前一版本有了重大升級,增強了編碼和自動化能力。該模型在代理編碼任務中表現出色,在SWE-bench Verified 等基準測試中的表現有所提高,從33.4% 上升到49%,優於包括OpenAI 的o1-preview 在內的公開模型。它在用於評估基於工具的問題解決能力的TAU 基準測試中也獲得了更高的分數:
- 零售領域:從62.6%增至69.2%
- 航空領域:從36% 增加至46%
這些優勢不會帶來任何成本或延遲,因此Claude 3.5 Sonnet 是複雜、多步驟開發任務的理想解決方案。 GitLab 等公司報告稱,DevSecOps 任務的推理能力提高了10%。 The Browser Company 也發現該模型在自動化基於Web 的工作流程方面非常出色。
該模型已與美國和英國人工智慧安全研究所合作進行了嚴格測試,以確保安全部署。它符合ASL-2 標準(Anthropic 負責任擴展政策的一部分),證實它符合更廣泛使用所需的安全基準。
Claude 3.5 Haiku:價格實惠、快速且功能強大的人工智慧
新的Claude 3.5 Haiku 模型專為速度和成本效益而設計,同時在多項評估中與Anthropic 之前最大的模型Claude 3 Opus 的性能相當。該模型在低延遲任務中表現出色,非常適合面向用戶的產品和資料密集型任務等即時應用。
Claude 3.5 Haiku 在SWE-bench Verified 上的得分為40.6%,在某些方面優於早期的Claude 模型甚至GPT-4o。它提供了準確的工具使用和改進的指令追蹤能力,使其能夠有效地從大型資料集(例如購買歷史、定價記錄或庫存資料)中產生個人化體驗。
該模型將於10 月下旬透過Anthropic 的API、Amazon Bedrock 和Google Cloud Vertex AI 推出。最初,它將支援純文字任務,預計很快就會推出圖像輸入功能。
人工智慧驅動的電腦使用處於公開測試階段
Anthropic 推出的最令人興奮的功能之一是Claude 使用電腦的能力。目前,Claude 已進入公測階段,開發人員可以使用Claude 像人類一樣執行任務,例如瀏覽螢幕、打字、點擊等。此功能可讓模型自動執行重複過程、進行開放式研究,甚至跨多個平台測試軟體。
像Replit 這樣的早期採用者已經在使用此功能來自動執行複雜的UI 導航任務,幫助他們的Replit Agent 產品在開發過程中評估應用程式。
在OSWorld 進行的測試中,Claude 3.5 Sonner 在獲得更多時間完成任務時得分為22%,優於其他得分僅為7.8% 的AI 模型。即便如此,該功能仍處於實驗階段,並且存在一些限制。需要滾動、縮放或拖曳的任務對於AI 來說可能很難順利執行。建議開發人員從低風險專案開始探索其潛力。 Anthropic 承諾將根據反饋不斷改進此功能。
確保安全部署
為了解決垃圾郵件、詐欺或錯誤訊息等安全風險問題,Anthropic 開發了新的分類器來監控和防止濫用電腦使用功能。這種主動方法有助於確保負責任地部署人工智慧驅動的自動化。
Claude 模型的資料集和訓練細節
根據Google Cloud 介紹,所有Claude 模型都透過幾種技術進行訓練:
- 無監督學習(從原始資料中的模式學習)
- 強化學習與人類回饋(RLHF)(透過人類回饋進行改進)
- 體質人工智慧(涉及監督學習和強化學習的過程)。
培訓基礎設施
Claude 3.5 Sonnet v2 使用亞馬遜網路服務(AWS) 和Google Cloud Platform (GCP) 提供的雲端服務進行訓練。開發使用的主要框架包括PyTorch、JAX 和Triton。
訓練資料來源
Claude 模型使用多種數據,包括:
- 截至2023 年8 月收集的公共互聯網信息,Claude 3.5 Sonnet v2 的培訓於2024 年4 月結束。
- 來自第三方的非公開數據,包括用戶、公司或僱用的服務提供者創建或標記的內容。
- Anthropic 內部產生的資料用於完善模型。
資料清理和過濾
為了確保資料的高品質,Anthropic 採用重複資料刪除(刪除重複資訊)和分類等方法來過濾掉不相關或低品質的資料。








