
Anthropic 宣布推出其最新的AI 語言模型Claude 3.5 Sonnet ,這是推出的Claude 3構建的全新“3.5”模型系列中的第一個。 Claude 3.5 可以撰寫文字、分析資料和編寫程式碼。它具有一個200,000 個token 上下文窗口,現已在Claude 網站上和透過API 提供。 Anthropic 也推出了Artifacts,這是Claude 介面中的一項新功能,可在專用視窗中顯示相關工作文件。
我們Oncloud AI透過本文詳細探討Claude 3.5 Sonnet。
大型語言模型(LLM) 的基準測試很麻煩,因為它們可能經過精心挑選,而且通常無法捕捉到使用機器生成幾乎任何可以想像到的主題的輸出的感覺和細微差別。但根據Anthropic 的說法,Claude 3.5 Sonnet 在某些基準測試(如MMLU(本科水平知識)、GSM8K(小學數學)和HumanEval(編碼))上的表現與GPT-4o 和Gemini 1.5 Pro 等競爭模型相當或優於它們。
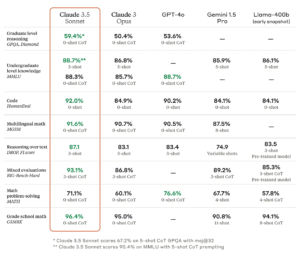 Claude 3.5 Sonnet 在衡量「推理」、數學技能、常識和編碼能力的基準測試中也優於Anthropic 之前的最佳模型(Claude 3 Opus)。例如,該模型在內部編碼評估中表現出色,解決了64% 的問題,而Claude 3 Opus 的問題解決率為38%。
Claude 3.5 Sonnet 在衡量「推理」、數學技能、常識和編碼能力的基準測試中也優於Anthropic 之前的最佳模型(Claude 3 Opus)。例如,該模型在內部編碼評估中表現出色,解決了64% 的問題,而Claude 3 Opus 的問題解決率為38%。
Claude 3.5 Sonnet 也是一個多模式AI 模型,可以接受圖像形式的視覺輸入,據報道,新模型在一系列視覺理解測試中表現出色。

粗略地說,視覺基準測試表明3.5 Sonnet 在從圖像中提取資訊方面比之前的模型做得更好。例如,你可以向它展示一張戴著橄欖球頭盔的兔子的照片,模型知道這是一隻戴著橄欖球頭盔的兔子,並且可以談論它。這對於技術演示來說很有趣,但對於可靠性至關重要的技術應用來說,這項技術仍然不夠準確。
介紹“Artifacts”
對於普通用戶來說,更值得注意的是一個名為「Artifacts」的新介面功能,它允許人們在對話的同時在專用視窗中與Claude 生成的內容(如程式碼、文字和網頁設計)進行互動。
Anthropic 將此視為將Claude.ai(其網頁介面)發展為團隊協作工作空間的一步,但它也能幫助人們在處理某些工作時不會在長時間對話的積壓中丟失內容。
Anthropic 表示,Claude 3.5 Sonnet 的運行速度是Claude 3 Opus 的兩倍。在性能大致相當的情況下,它的價格也更便宜——在API 中,新的3.5 型號每百萬輸入令牌的成本為3 美元,每百萬輸出令牌的成本為15 美元。相比之下,Opus 每百萬輸入代幣的成本為15 美元,每百萬輸出代幣的成本為75 美元。
除了網站和API 之外,Claude 3.5 Sonnet 還可透過Claude iOS 應用程式訪問,付費用戶的使用限制更高。該模型還可透過亞馬遜的Bedrock 和Google Cloud 的Vertex AI 平台使用。








